on
Decoding CAN messages with DBC files
DBC files are a proprietary Vector file format that encodes information about how data is packed into a CAN frame, allowing you to pack and unpack the data. The open source equivalent is the KCD file used by Kayak, that essentially encodes the same information in a more verbose format. Vector's DBC files have been reverse engineered by basically everyone, and a lot of open source tools support it, as well as paid tools (like CANoe, Kayak, PCAN-Explorer, CANApe, etc.).
We were lucky to get a sponsorship this term from Phytools, who generously donated various PEAK PCAN-USB dongles to our solar car team. These were a much-welcome addition to our old setup, which consisted of either the one LAWICEL CAN-USB dongle that we shared (which is generally needed, as the Tritium WaveSculptor 20 Configuration Tool requires a slcan interface), or our home-built solution that dumped CAN traffic over UART. We were also able to obtain licenses for PCAN-Explorer, which allows us to work in a Windows GUI.
Before graduation, I wanted to begin a transition over in our codegen repository towards DBC files.
History
To provide some context, currently, the codegen-tooling repository serves as a dependency in various projects across the Midnight Sun Solar Rayce Car team, beginning from MS XII (2018). It was originally intended to only serve as a general template renderer, such that it would store the data, while templates would be stored in their respective project repositories. The idea was that we would invoke the codegen tool as a build step from each project's build system when either the template or the data changed, and then it would generate output files.
For MS XI (2016), we had a master Google Spreadsheet that contained every single allocated CAN Message ID, and what each bit represented. Then we had a bunch of macros that hid how CAN arbitration IDs were built for each node (by performing the proper shifting to append device IDs that were part of our protocol), and then a union that you would manually fill in for the 64-bits of data. It was up to each person writing code to correctly reference this spreadsheet and perform the packing/unpacking on the right pieces of data.
cat devices.inc
# // DEVICE(name, id)
# DEVICE(BMS, 0x1)
cat bms.inc
# // CAN(name, id, format)
# // Valid formats: BOOL, UINT8, UINT16, UINT32, UINT64, FLOAT, INT16
#
# // To Telemetry:
# CAN(VOLTAGE_READING, 0x1, UINT16)
# These files were then #included in a header, and copious amounts of macros
# were used to build the Message IDs.For MS XII (2018), we decided that we could do better, and created a codegen tool that basically specified CAN Messages and the values types that are transmitted. This tool was simply basically a wrapper around a Python templating language, so that the output is agnostic of whatever language the generated source files are (and so we used this to generate JS, Go, and C code). This worked pretty well, and the only real pain point was integrating it into our build process for each project. This was codegen-tooling.
I still maintain that at the time, this was the right decision to do. I wrote the codegen script in a few hours one weekend, and then we basically never had to touch it again. Changes made to the Message protos were updated relatively painlessly, and adding new language support wasn't difficult, since templating languages are pretty easy to pick up. At the time, this decision made sense. It would allow us to only invoke codegen when the dependencies changed, which could be tracked in the build system. It would also allow us to customize where the outputs were, and reuse the same data and rendering capabilities so that the project was language-agnostic.
We had evaluated open source solutions and looked into cantools, but it was still rather immature at the time. They only recently added floating point and C code generation support (which I contributed portions of). Plus, it didn't really play too well with our proposed CAN protocol, which had the notion of Acknowledgements for "Critical" Messages that were programmatically requested in firmware, which was intended to ensure that the Message was received and processed in the application code.
codegen-tooling
Our codegen project took in a proto that defined how fields in the CAN frame would be packed. We chose a proto in order to validate as much of the data as possible at compile time. We had considered YAML and JSON, but those would require our own checks when serializing, which we would get for free from a proto.
For simplicity, our protocol only handled 1 type per Message. As such, a Message could only contain a maximum of either:
- 1 Signal of 64-bits
- 2 Signals of 32-bits
- 4 Signals of 16-bits
- 8 Signals of 8-bits
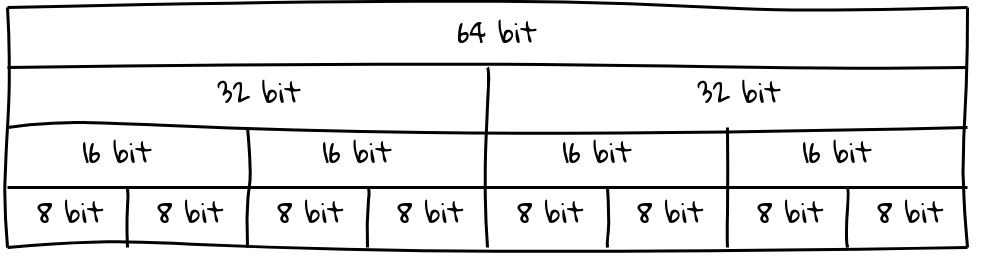
Here's a sample Message:
msg {
id: 32
source: PLUTUS
# target: DRIVER_DISPLAY, TELEMETRY
msg_name: "battery vt"
msg_readable_name: "battery voltage temperature"
can_data {
u16 {
field_name_1: "module_id"
field_name_2: "voltage"
field_name_3: "temperature"
}
}
}Initially, this system allowed us to cover all our use cases. It allowed us to generate code to parse CAN data in our telemetry system server, and also handled the code generation for our microcontrollers to pack and unpack CAN frames. This worked well, and we never had any problems with this.
But issues arose when we began trying to shoehorn the project into use-cases that it wasn't intended to support.
Assumptions change, requirements change
We had designed this under the assumption that everyone interested in the contents of CAN messages would be capable of understanding how the ASCII proto worked, and were comfortable coding.
I'm not exactly sure when those directives changed (or how it changed), but ultimately it ended up becoming a dependency that was used as a library, containing all the generated code. In an attempt to avoid dealing with the headaches that git submodules bring, we had initially decided that we would tag releases on GitHub, since we didn't always want to live at HEAD. Somehow, this also changed, and we ended up with releases at every commit.
We also ended up having to maintain a separate Confluence page of the CAN Message definitions, which never was in sync with the proto. And since the Telemetry server required some know-how in setting up, we had a separate hand-maintained script to decode CAN traffic. Not only was this fragile (as every change to the codegen project meant remembering to update the script and the Confluence page), but error prone. We could have spent time converting the script to a codegen template, but this would have been a significant piece of work.
But that's not really the point of this post. Switching to a DBC had the following immediate benefits:
- We had assumed that people reading telemetry data off the CAN bus or adding new Signals to CAN frames would be comfortable with code, and therefore reading through the CAN Message definition would be trivial. This turned out to not be the case, and lots of new members seemed to find it difficult to understand how to read the
protofile, even though it was just ASCII. Having aDBCmeant that you could point people to a GUI viewer (that was either freeware or open source) and let them explore for themselves, and reduced the friction to add new messages and data. - There was still a significant amount of work needed to integrate new messages into our scripts that we used to dump data. Using a
DBCwould allow us to get rid of these scripts and the maintenance effort required for these. We could probably add support in our codegen tool, but the open source tooling forDBCs was finally mature enough. - It allowed us to take advantage of other industry tooling (PCAN-Explorer, CANape, etc.) that people have internship experience working with.
- We had designed our CAN protocol with somewhat odd alignment rules that made coding it easier (it supports up to 8 signals of 1 byte, up to 4 signals of 2 bytes, up to 2 signals of 32 bytes, or 1 signal of 64 bytes—in other words, every single signal must be of the same length). We've been considering enhancing it to not require these alignment rules, in order to pack more under a single Message ID, and retrofitting our
prototo encode that logic is work that theDBCgives for free. - Technically the Device ID that we were using wasn't strictly necessary, as
the set of all Message IDs that are sent by each node would be specified in
the
DBC. This would free up CAN IDs that we were squatting, with the idea that we could take advantage of hardware filtering for certain messages. We could have done this with theproto, but work would have been needed to ensure we weren't put in a position where arbitration ID collisions could occur. - Our experiment with Acknowledgement Messages in our protocol had its own
share of complexities, and it was debatable whether that was necessary. We
could have instead moved to a periodic model where every Message is cyclic,
and then if the Message containing a Signal isn't received within a
predetermined number of periods, that would allow us to detect that things
weren't all okay. While
DBCfiles don't really change this, it makes the switch slightly easier knowing that the protocol was probably going to change as well. - Integrating it into our build system was a pain. We had designed it to be invoked as a build step to generate intermediate source files that would be consumed in the build, but this never ended up happening. Instead, it basically became a wrapper around submodules (just hidden as tagged releases). While
DBCfiles don't directly address this (since this is more of a change that should happen with our build system), it simplifies the process slightly.
The Migration Plan
As such, I wanted to gradually migrate things over instead of doing one giant change, in case things went horribly wrong and problems only manifested after extended periods of time. The general plan for the stages of the migration was as follows:
- Run our current codegen-tooling setup alongside with the
DBCfile, and use this time to validate tooling and that theDBCfile is being generated correctly. No changes to code running on microcontrollers. - Switch pack/unpack logic to use the
DBCfile on a microcontroller-by-microcontroller basis - Deprecate the old codegen-tooling setup, and use the
DBCfile as the source of truth - Cut over to the
DBCfile
I wrote a shim script that allowed us to generate a DBC file from the old
ASCII proto files, which required some additional information not included
in the proto (like the Acknowledgements that were programmatically generated in firmware).
This provided us with a stop-gap that allowed us to run both at the same time,
until we were ready to deprecate the old setup.
I also ended up creating DBC files for each of our other CAN bus devices that we don't control the CAN protocol for. This includes our motor controllers—the Tritium WaveSculptor 20s (since we can't afford the WaveSculptor 22s)—and the ELCON UHF Charger. I also created DBCs for the Tritium WaveSculptor 22s, although that hasn't been tested (so use at your own risk). These were created using the free Kvaser Database Editor tool.
I've included some sample data in the repository that you can replay over a virtual SocketCAN bus.
# Grab the repository
git clone https://github.com/wavesculptor-20-dbc
cd wavesculptor-20-dbc/
# Load kernel modules
sudo modprobe vcan
# Bring up vcan interface
sudo ip link add dev vcan0 type vcan
sudo ip link set up vcan0
# Replay the CAN logs using canplayer or your tool of choice
canplayer -I examples/candump-2019-01-09_224207.log vcan0=slcan0 &
# Monitor the replayed data
cantools monitor --channel vcan0 dbc/wavesculptor_20.dbc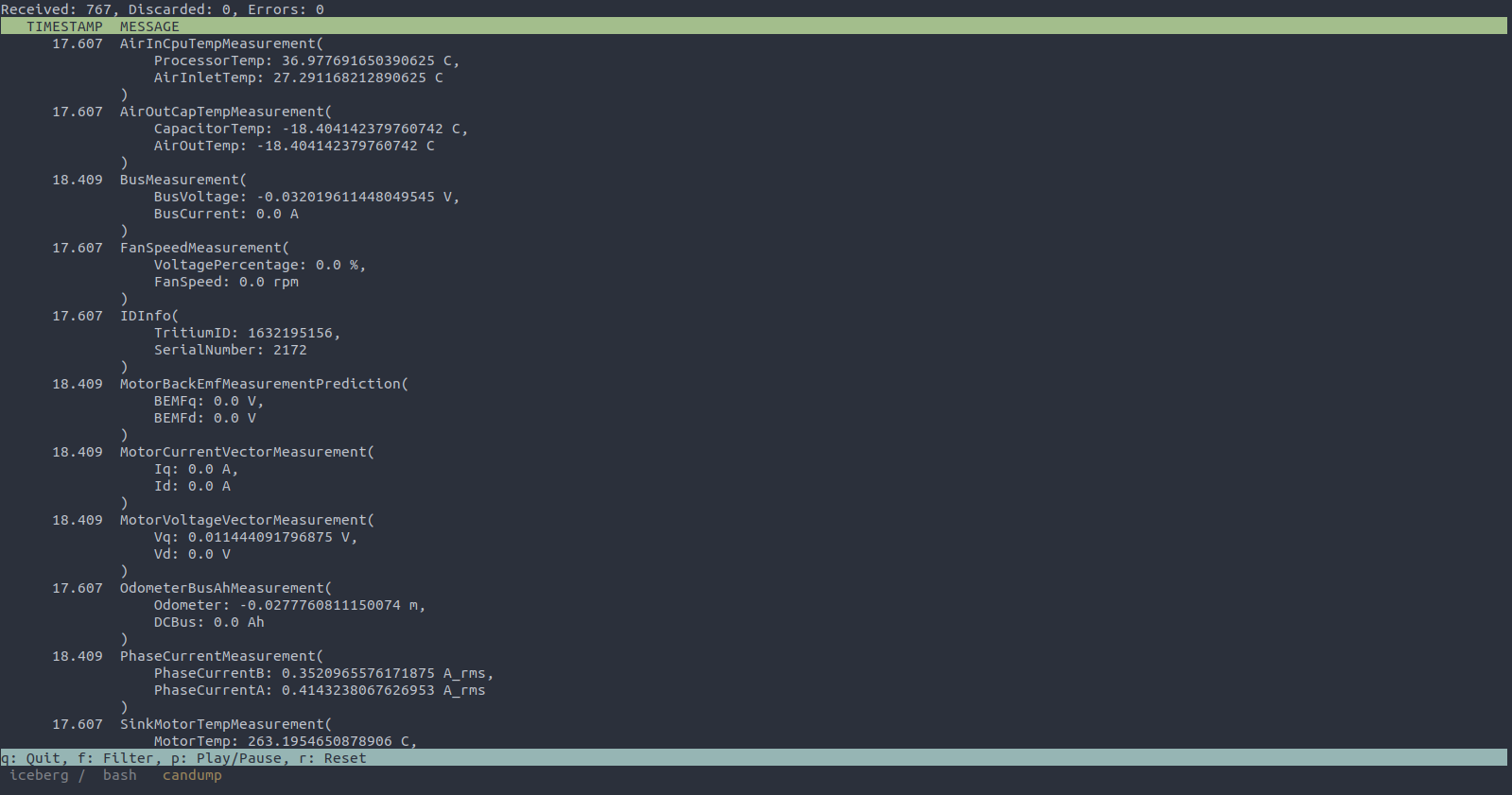
In the process, I ended up submitting various patches upstream to cantools in order to better support our use-cases. This included support for floating type Signal values, various C code generation enhancements, displaying multiplexors in the monitor subparser, and pagination support, among others.
We've rolled out the DBC, so now we're just validating that everything is working as expected before cutting over all the codegen stuff to use the DBC. So far, this has been extremely well-received by all the members of the team, and is much easier to use. I'm a firm believer that you should have access to tools that enable you to do your job effectively.
We don't have enough licenses of PCAN-Explorer to go around, so not everyone can have this.
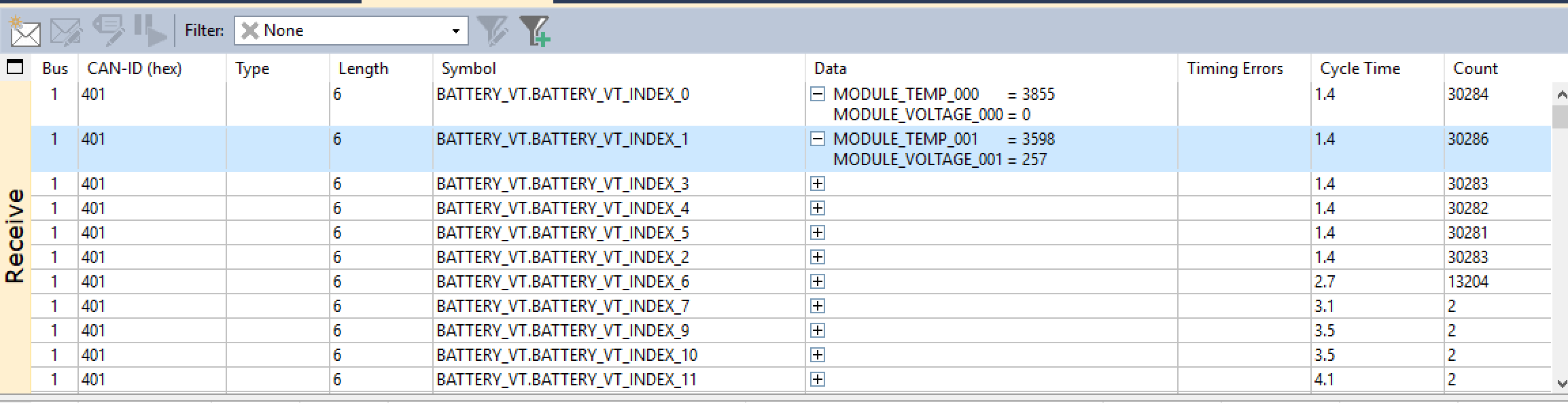
But that's fine, because thanks to open source, we have this:
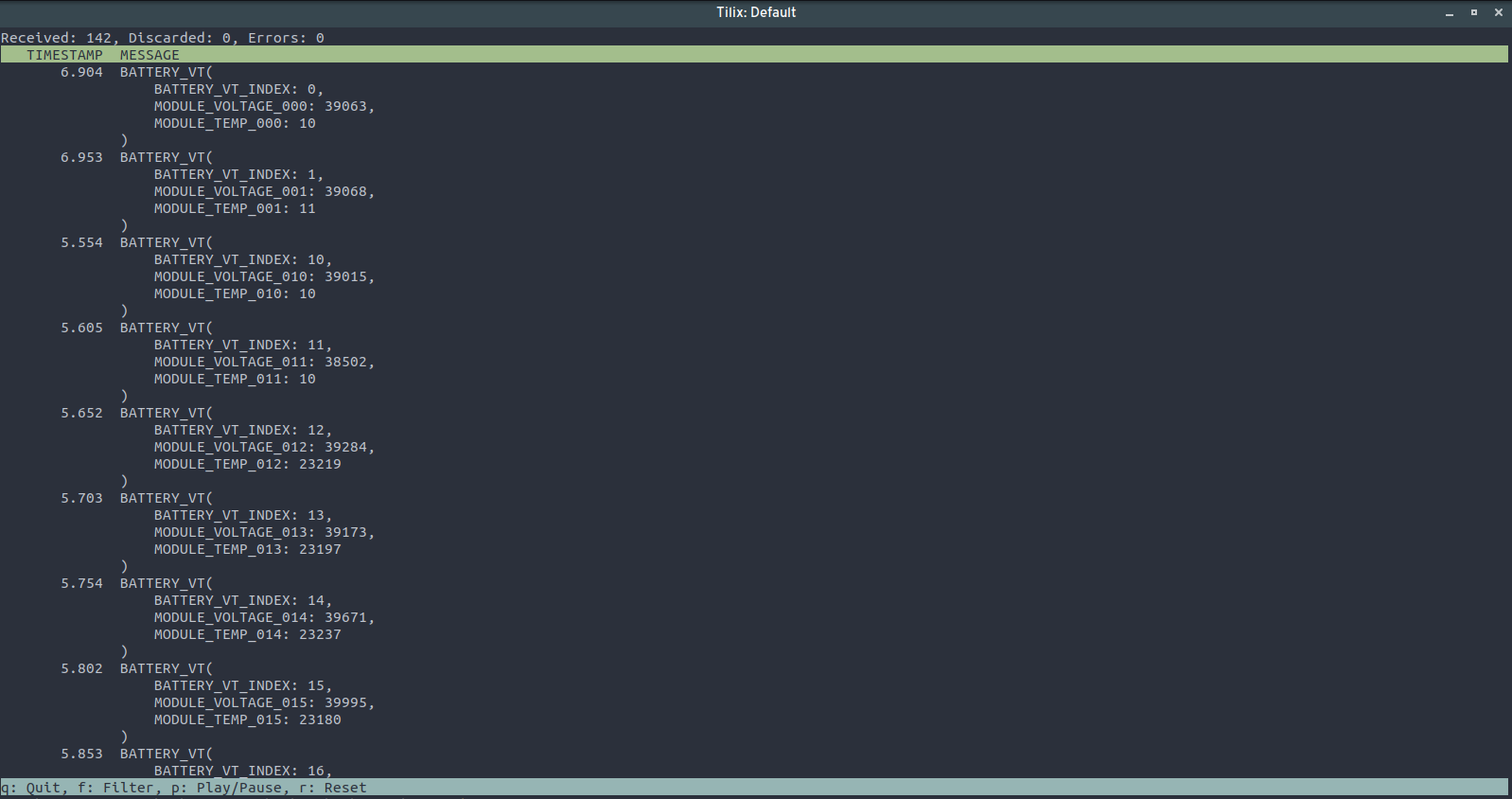
And if that's not to your liking, there are multiple other CAN projects that deal with DBC/KCD/SYM files.
TL;DR
# Plug in your CAN interface
# ...
# Bring up SocketCAN interface at 500 kbps
sudo ip link set can0 up type can bitrate 500000
# Use system_can.dbc to decode the CAN messages
cantools monitor system_can.dbc
# Profit!!!